

ディープラーニング
人間の脳神経のニューロンを数式でモデリングし、層状に並べたものがニューラルネットワークと呼ばれ、それを人間の脳の様に深く複雑にしたものが深層学習(ディープラーニング)と呼ばれます。
ディープラーニングは世界中で注目され、画像処理だけでなく自然言語処理や音声認識、ゲーム理論など様々な分野で用いられています。例えば、囲碁の人工知能で有名なAlpha GoやGoogle翻訳などはディープラーニングの技術を用いています。
この様に世界が注目している技術、最先端の技術を用いて研究しています。
研究内容
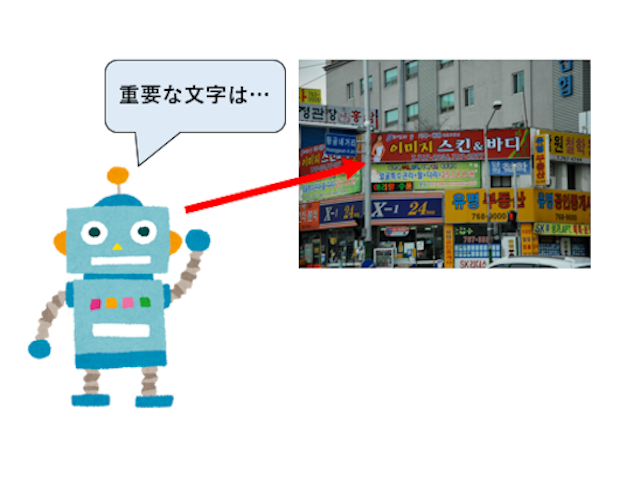
情景画像中の重要な文字の検出
この研究では文字の視覚的特徴から重要度を計算します。それを用いて人間が重要だと思う文字を検出し、情報の取捨選択を行い、効率的な情報収集を実現することを目的としています。この研究によって人間の視覚特性を備えたロボットの開発に応用できると考えられます。
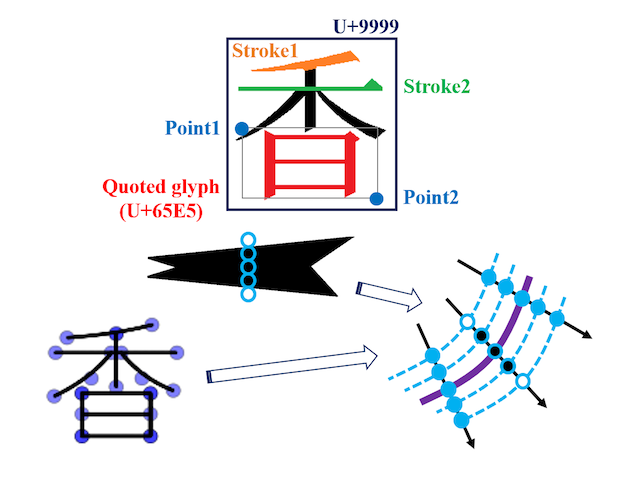
グリフを利用した学習データ生成
日本語は多言語と比較して文字種が多く、文字認識の際に必要な学習データを収集するためには多大なコストがかかります。本研究では文字骨格データベースを利用した文字画像自動生成によって、学習データ収集の簡略化及び文字認識の高精度化の両立を検討しています。
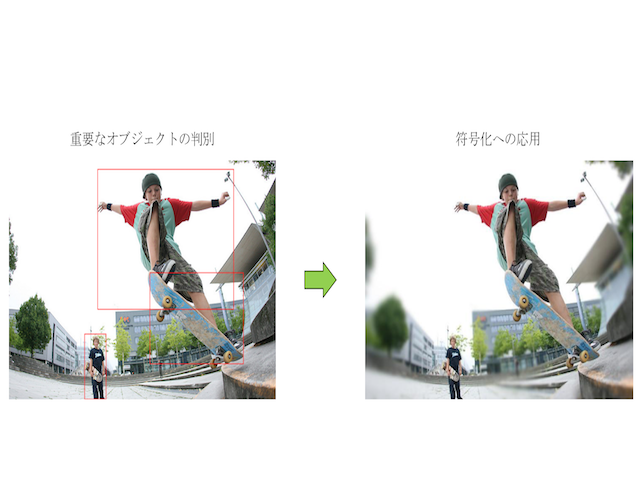
画像中の重要オブジェクトの判別
画像中には重要な情報がいくつも含まれており、そのうちの一つが人の注目を集める物体(オブジェクト)です。 この研究では、ディープラーニングを用いた高精度な物体検出、および注目度の予測によりより重要なオブジェクトを判別します。その後、符号化などに応用します。
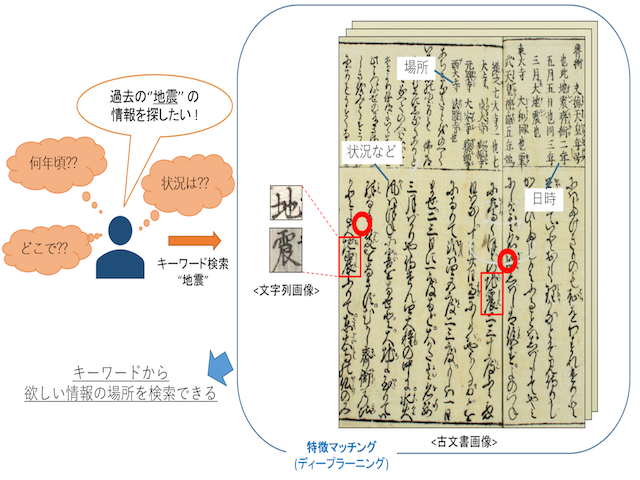
古文書の画像の古典文字の検索
古文書に記述されている過去の文化や歴史・災害の記録等の有益な情報を活用しやすくするため、膨大な古文書データ内からキーワード入力でその文字列が存在する箇所を検索する方法の検討を行っています。現在はマッチングに使用する文字画像生成にも取り組んでいます。
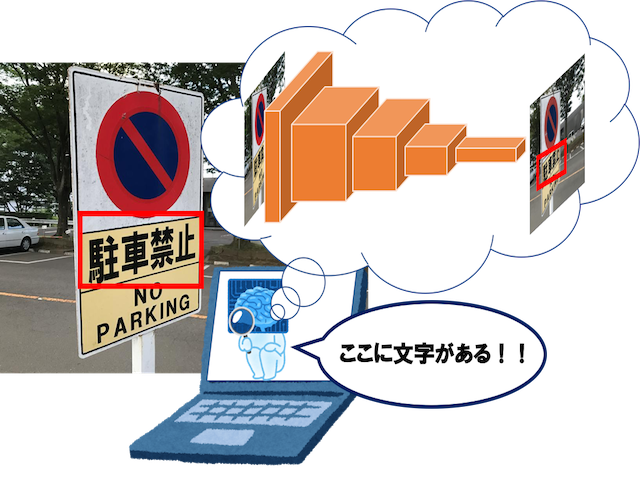
情景画像中の文字領域の検出
画像の中で文字がある場所を探す研究です。私達の周りには様々なフォントや色の文字があり、それらを全て検出するのは困難です。そこで、ニューラルネットワークを用いて研究しています。これに文字認識が加われば自動翻訳など様々なアプリケーションに応用できます。
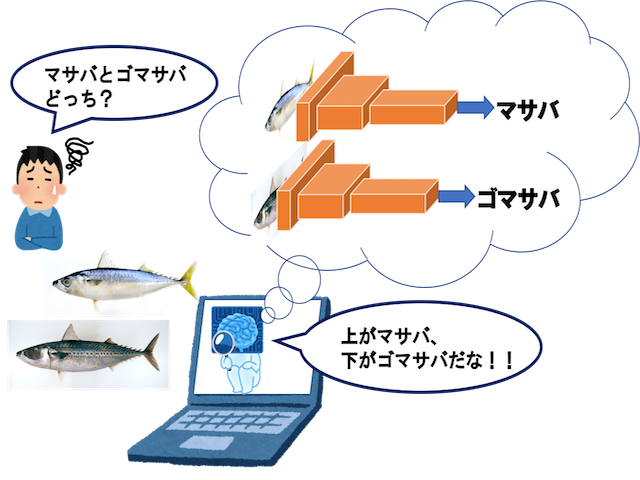
サバ判別システムでのサバの識別
サバにはマサバとゴマサバがいます。それらはお腹の模様で人が見分けるので人的コストが大きく、加えてお腹の模様では分かりにくいサバがいることなどの問題があります。それらの解決のためにCNNを用いて機械で自動的に、かつ高精度に分類することを研究しています。
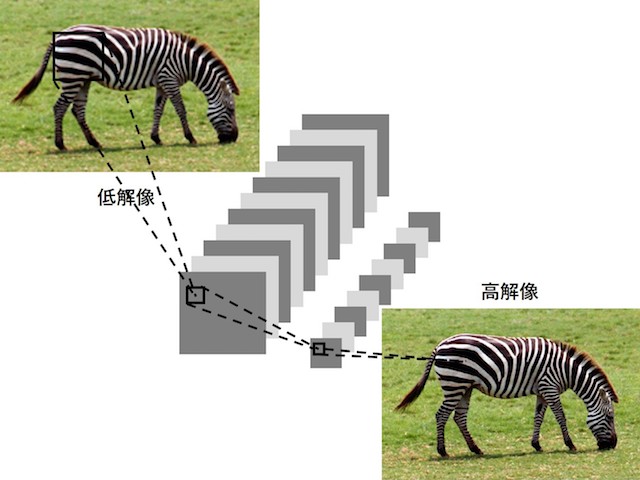
画像の超解像による高解像度化
現在は通信やセンサー等の制限があり、私たちの使う画像のほとんどはネットでの通信中で圧縮されて低解像になり、その時に大事な情報が失われることがあります。そこで本研究ではニューラルネットワークを用いて、低解像度の画像を高解像度にすることを目的としています。
工学研究科 通信工学専攻 通信システム工学講座 画像情報通信工学分野
Useful Links
Contact Us
荒巻字青葉6-6-05
電気系1号館 621・641号室
Phone: 022 795 7088
Fax: 022 795 7090
2016 © All Rights Reserved.