

文字検出・認識
近年ではディープラーニングという画期的な技術の台頭により、このような検出及び認識の精度は格段に向上しています。 本研究室ではディープラーニング以外にもOCRなどの技術や画像処理を用いて、文字検出・認識を試みています。
また、それらの技術を他の技術と組み合わせた応用研究も行なっています。
研究内容

テキストを含む画像の符号化
高周波をカットする既存の画像圧縮では、画像中に含まれる文字が読みづらくなってしまうという問題があります。本研究では、文字検出とスパースコーディングを組み合わせることで、文字部分をきれいに保存しつつ画像の容量を削減する手法を検討します。
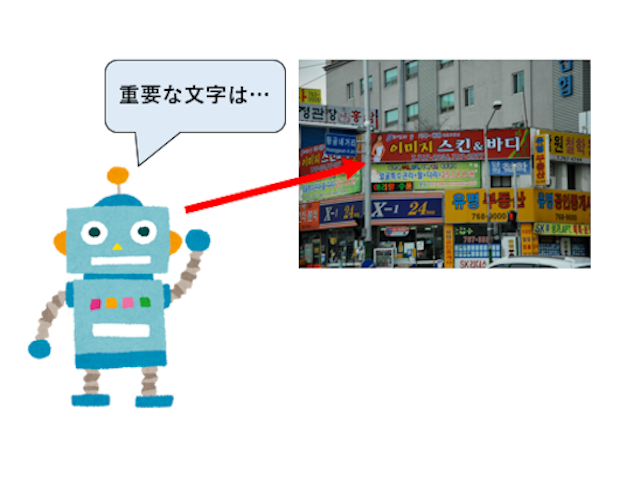
情景画像中の重要な文字の検出
この研究では文字の視覚的特徴から計算できる重要度という値を用いて人間が重要だと感じた文字のみを検出し、効率的な情報収集を実現することを目的としています。この研究によって人間の視覚特性を備えたロボットの開発に応用できると考えられます。
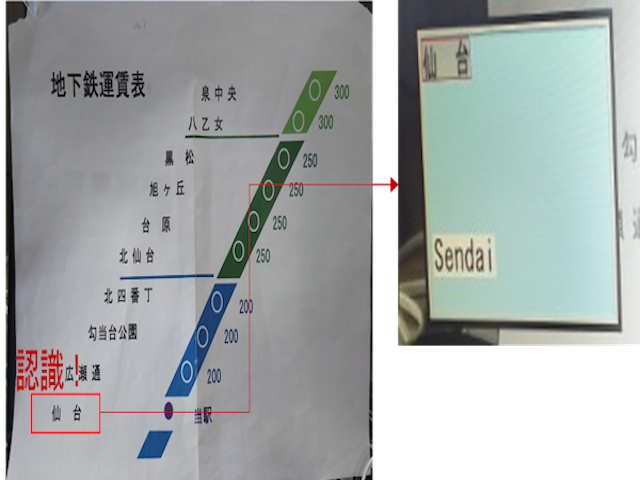
文字認識のアプリケーション応用
画像中の駅名情報を抽出するアプリケーションを開発する研究です。 カメラを用いて情景画像を撮影し、特定の単語1つに対して和英翻訳を行うようなアプリの開発を行っています。和英翻訳以外の新たな応用化を考えることが現在課題となっています。
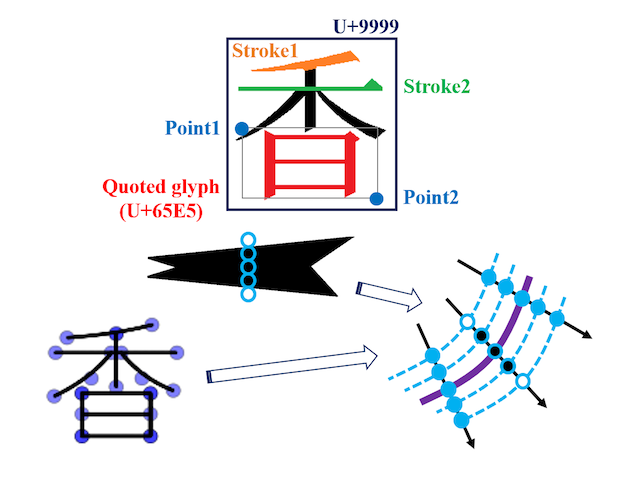
グリフを利用した学習データ生成
日本語は多言語と比較して文字種が多く、文字認識の際に必要な学習データを収集するためには多大なコストがかかります。本研究では文字骨格データベースを利用した文字画像自動生成によって、学習データ収集の簡略化及び文字認識の高精度化の両立を検討しています。
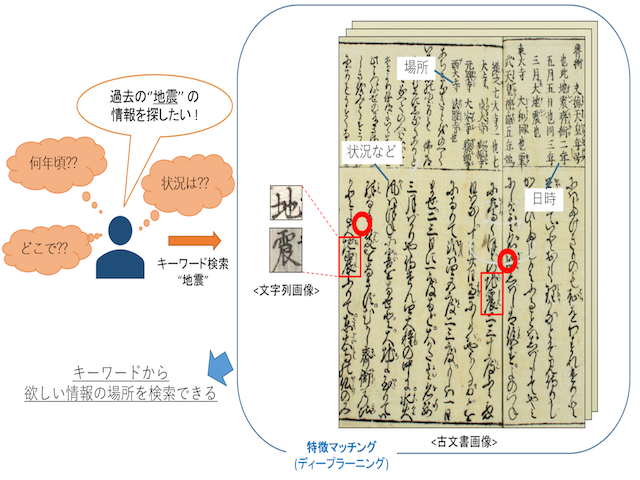
古文書の画像の古典文字の検索
古文書に記述されている過去の文化や歴史・災害の記録等の有益な情報を活用しやすくするため、膨大な古文書データ内からキーワード入力でその文字列が存在する箇所を検索する方法の検討を行っています。現在はマッチングに使用する文字画像生成にも取り組んでいます。
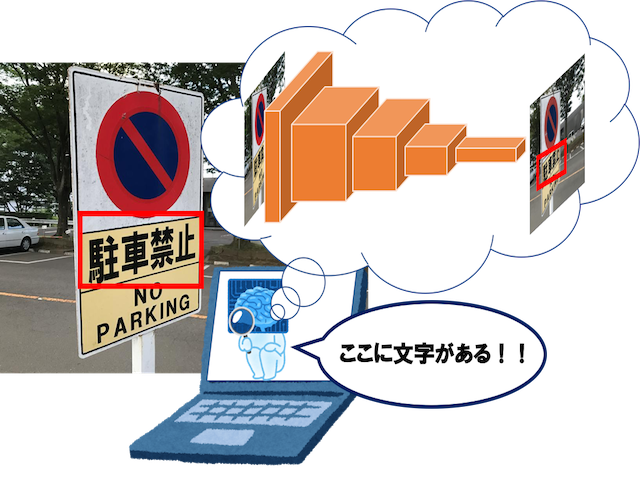
情景画像中の文字領域の検出
画像の中で文字がある場所を探す研究です。私達の周りには様々なフォントや色の文字があり、それらを全て検出するのは困難です。そこで、ニューラルネットワークを用いて研究しています。これに文字認識が加われば自動翻訳など様々なアプリケーションに応用できます。
工学研究科 通信工学専攻 通信システム工学講座 画像情報通信工学分野
Useful Links
Contact Us
荒巻字青葉6-6-05
電気系1号館 621・641号室
Phone: 022 795 7088
Fax: 022 795 7090
2016 © All Rights Reserved.