

文字生成
文字認識において、高精度な認識を実現するためには適切な文字画像を多数収集しなければなりません。しかし、日本語や古典籍については文字種の多さやデータの希少性から従来方法でのデータ収集が困難であるという問題があります。
本研究室では、文字生成モデルを利用した学習データの自動生成に注目し、データ収集の低コスト化及び認識精度向上のための研究を行っています。 また、日本語のフォント製作に必要な文字は6000種以上に渡り、デザインには2~3年程度かかると言われているなど、人件費や時間的コストが大きいです。
そこで本研究室は、文字生成技術を用いることによって一定量のサンプルから自動的にフォントを生成し、フォントデザインを補助する研究も行っています。
本研究室では、文字生成モデルを利用した学習データの自動生成に注目し、データ収集の低コスト化及び認識精度向上のための研究を行っています。 また、日本語のフォント製作に必要な文字は6000種以上に渡り、デザインには2~3年程度かかると言われているなど、人件費や時間的コストが大きいです。
そこで本研究室は、文字生成技術を用いることによって一定量のサンプルから自動的にフォントを生成し、フォントデザインを補助する研究も行っています。
研究内容
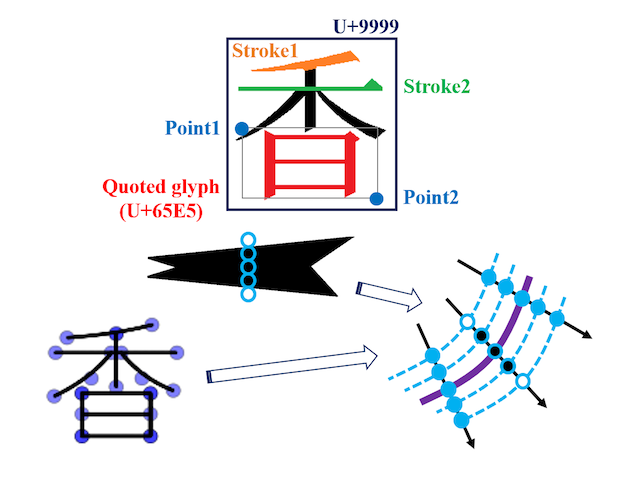
グリフを利用した学習データ生成
日本語は多言語と比較して文字種が多く、文字認識の際に必要な学習データを収集するためには多大なコストがかかります。本研究では文字骨格データベースを利用した文字画像自動生成によって、学習データ収集の簡略化及び文字認識の高精度化の両立を検討しています。
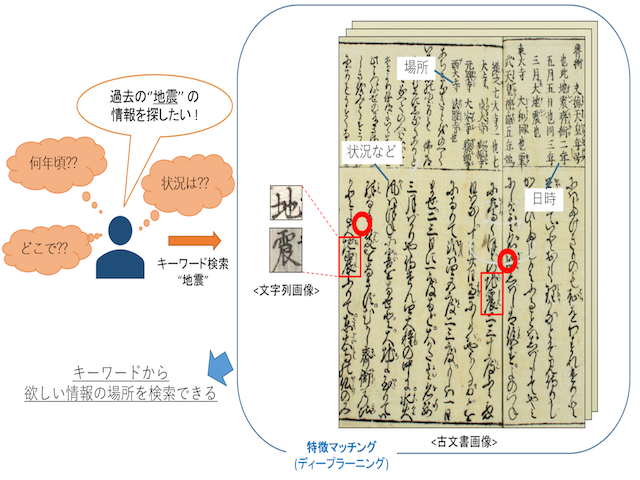
古文書の画像の古典文字の検索
古文書に記述されている過去の文化や歴史・災害の記録等の有益な情報を活用しやすくするため、膨大な古文書データ内からキーワード入力でその文字列が存在する箇所を検索する方法の検討を行っています。現在はマッチングに使用する文字画像生成にも取り組んでいます。
工学研究科 通信工学専攻 通信システム工学講座 画像情報通信工学分野
Useful Links
Contact Us
荒巻字青葉6-6-05
電気系1号館 621・641号室
Phone: 022 795 7088
Fax: 022 795 7090
2016 © All Rights Reserved.