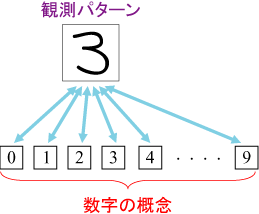
 パターン認識とは、観測されたパターンをあらかじめ定められた概念(クラス)の1つに対応させる処理のことです。例えば数字を認識するのであれば、与えられた画像(パターン)を0から9までのいずれかに対応させる処理になります。この、人間にとっては易しい処理も機械(コンピュータ)には非常に難しく、間違いのない認識を実現するために様々な研究がされています。
パターン認識とは、観測されたパターンをあらかじめ定められた概念(クラス)の1つに対応させる処理のことです。例えば数字を認識するのであれば、与えられた画像(パターン)を0から9までのいずれかに対応させる処理になります。この、人間にとっては易しい処理も機械(コンピュータ)には非常に難しく、間違いのない認識を実現するために様々な研究がされています。統計的パターン認識手法の高精度化を目指して理論研究を行なっています。特に、少数サンプル問題の解決とパターンの分布形状の高精度推定の二点を目標とし、様々な手法を提案しています。
パターン認識とは、観測されたパターンをあらかじめ定められた概念(クラス)の1つに対応させる処理のことです。例えば数字を認識するのであれば、与えられた画像(パターン)を0から9までのいずれかに対応させる処理になります。この、人間にとっては易しい処理も機械(コンピュータ)には非常に難しく、間違いのない認識を実現するために様々な研究がされています。
コンピュータによるパターン認識は、通常特徴抽出と識別の2つの過程で行われます。
特徴抽出とは、対象を区別できるような情報を観測パターンから取り出す処理です。コンピュータで扱いやすいように、情報はすべて数値化されます。取り出された情報を特徴と呼びます。花の種類を認識するなら、花弁の色・数・形などが特徴になります。どのような特徴を抽出するかはパターン認識の性能を決める重要な要素ですが、何が有効な特徴となり得るかは認識しようとする対象によって異なり、設計者の経験と勘によるところが大きいのが事実です。
識別は、得られた特徴を用いて観測されたパターンがどのクラスに属するかを判断する処理です。観測パターンから得られた数値を対象とするので、識別の理論は様々な認識対象に対して適用できます。
 識別の手法は、大きく統計的アプローチと構文解析的アプローチに分類されます。
識別の手法は、大きく統計的アプローチと構文解析的アプローチに分類されます。
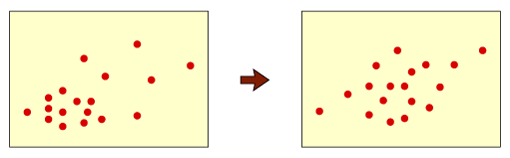
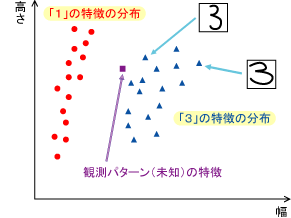
統計的アプローチでは、認識対象となるそれぞれのクラスについて、あらかじめ多数のデータを収集しておきます。そして、収集されたデータから得られた統計量(平均、分散など)をもとに、観測パターンが各クラスに属するもっともらしさを評価します。たとえば、数字の幅と高さを特徴にしたとします。「3」と「1」の画像を大量に収集し、それらの画像の幅と高さを求めておきます。例えば右図で、●は様々な「1」の幅と高さを2次元平面上にプロットしたもの、▲は「3」を同様にプロットしたものです。「1」か「3」か分からない数字を観測したとき、その幅と高さが■のようになったとして、これは「1」と「3」のどちらでしょうか。一概には言えませんが、おそらく「3」と判断するのが適当だろうと考えられます。なぜなら、既知の多くの「3」の特徴が近くに分布しているからです。
もちろん0から9までの数字がこのような単純な特徴だけで認識できないのは明らかです。一般に現実の認識問題の特徴は抽出も複雑で数も多く(高次元)、どのクラスに属するかを判断するのは難しい問題になります。
様々な特徴に対応できる一般的な方法として、確率分布を考える方法があります。クラスごとに多くのデータを収集して特徴を求め、特徴の確率分布を求めておきます。未知の観測パターンから特徴を求め、それが各クラスに属する確率を計算します。最も確率の高いクラスが一番もっともらしいクラスであると判断する方法です。
一方、構文解析的アプローチでは、各クラスのパターンがある規則(文法)に従って生成すると考え、観測パターンを生成するのはどのクラスの規則であるかを判断することでクラスを判定します。例えば「3」であれば、「曲線+鋭角+曲線」、「5」であれば「横線+直角+縦線+鋭角+曲線」という規則が考えられます。これらのうち未知の観測パターンを生成することのできる規則を判定することで「3」か「5」かを判定します。
特徴抽出により得られた特徴をもとに、いかに高精度に識別を行うかはパターン認識における中心テーマの一つです。様々な認識対象に適用できる万能な認識手法を探求しています。特に統計的アプローチにおける識別の高精度化・高速化の研究を行っています。
統計的識別理論では、クラスごとに多くのデータを収集して特徴を求め、特徴の確率分布を求めてこれを元に認識します。未知の観測パターンから特徴を求め、それが各クラスに属する確率を計算し、最も確率の高いクラスが一番もっともらしいクラスであると判断します。
観測パターンに雑音が含まれる場合、特徴の分布形状は雑音によって変化すると考えられます。従来法では、識別に利用する確率分布はその分布形状の変化にかかわらず同じものを使用していたため、雑音が含まれたデータを高精度に認識することは難しかったのです。これに対し、特徴ベクトルの一部の要素に雑音が加わった場合に分布形状がどのように変化するのかを考察し、その変化を反映させて確率分布を変更する手法を考案しました。本手法は従来の統計的な手法を補うもので、雑音を含むデータに対して高い識別能力をもつだけでなく、雑音が含まれないデータに対する悪影響がないという特徴があります。
 探索方法の学習による識別の高速化
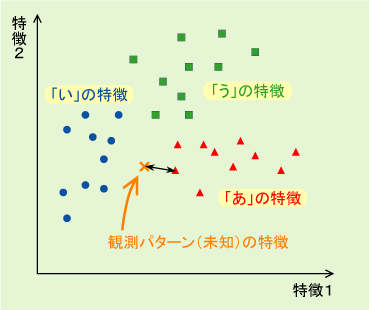
探索方法の学習による識別の高速化識別方法の一つに、最近隣識別法と呼ばれる方法があります。これは、クラスごとに確率分布を考えるのではなく、すべての収集データ(サンプル)と観測された未知パターンとの距離を計算し、距離の最も近いサンプルのクラスであると認識する方法です。例えば右図では、未知パターンはクラス「あ」のサンプルと最も近いので、「あ」と認識されることになります。
この方法はデータの分布を正規分布と仮定する必要がないためどのようなデータに対しても適用できますが、すべてのサンプルとの距離を計算する必要があるため、認識する際の計算量が膨大なものになります。
これを改善するために、あらかじめサンプルを分類しておき、比較する必要ないサンプルとの距離計算を省略することで識別を高速に行う手法を開発しました。データにもよりますが、高次元の特徴を用いた場合に特に改善の効果が大きく、6倍程度の高速化が実現できました。
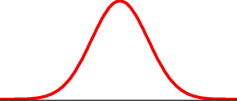 統計的アプローチの中に、データの確率分布が正規分布であると考えて識別を行う方法があります。正規分布とは右図のように平均を中心として左右対称な分布です。正規分布を使う理由は、世の中の多くの分布が近似的に正規分布に従っていることと、数学的に扱いやすいことがあります。
統計的アプローチの中に、データの確率分布が正規分布であると考えて識別を行う方法があります。正規分布とは右図のように平均を中心として左右対称な分布です。正規分布を使う理由は、世の中の多くの分布が近似的に正規分布に従っていることと、数学的に扱いやすいことがあります。
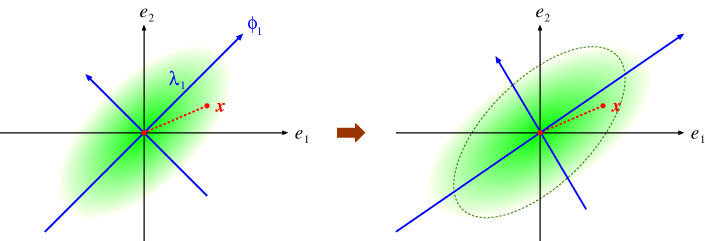
正規分布を仮定した手法はよく研究され、データが正規分布に従う場合は高精度な認識ができることが知られています。しかし、実際には正規分布に従わないデータも数多く存在します。そのような正規分布に従わないデータを高精度に認識するために、データから得られた特徴をあらかじめ正規分布に近づけるように変換し、変換後の特徴を用いて認識を行うことで高精度化を達成する手法を検討しています。
どのような分布であっても正規分布に近づけることを可能にするために、指数型ベキ変換と呼ばれる変換を利用します。この変換は
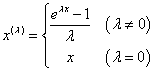
で定義され、λの値により様々な変換を行うことができます。データに応じてλの値を適切に定めることにより、観測データの特徴を正規分布に近づけ、認識性能を向上させることに成功しました。